AI classification and categorization are quickly becoming foundational tools in managing growing volumes of enterprise data, especially in regulated sectors.
In fact, AI-powered data classification tools are projected to automate 70% of Personally Identifiable Information (PII) classification tasks by 2024.
By applying AI to the process of data classification, organizations can reduce manual work, improve accuracy, and meet standards and regulations more effectively.
In this article, we’ll cover:
- What AI classification and AI categorization mean and how they work
- Why these technologies matter for compliance-driven industries
- 3 common AI data classification techniques (rule-based, ML, and NLP)
- Practical steps to implement AI classification in your organization
- 5 known challenges and how to address them
- Emerging trends in AI categorization and classification tools
This guide is designed to help IT and compliance leaders understand the value of AI classification and learn how to best integrate it into their data management strategies.
Understanding AI Classification and AI Categorization
As data accumulates, there’s growing pressure to keep it organized, accessible, and compliant. AI classification and categorization are two related but distinct processes that help solve this problem.
They streamline how data is grouped, labeled, and structured, enabling faster access, more efficient use, and reduced risk of non-compliance.
What is AI classification?
AI classification is the process of using algorithms, primarily machine learning models, to assign data to specific, predefined categories. These models analyze the content, structure, and context of each data item to determine the most appropriate label.
How it works:
- Data is ingested and analyzed based on text, metadata, and usage context.
- Models are trained on labeled datasets to recognize patterns and associations.
- When new data is received, the AI applies the learned patterns to classify it accurately.
Common use cases:
- Email filtering — Automatically sorting emails into categories like confidential, promotional, or urgent.
- Data culling for ediscovery — Filtering and reducing the volume of data so teams can focus only on the most relevant and necessary information.
- Document management — Flagging HR files, financial records, or personally identifiable information (PII).
- Compliance monitoring — Detecting and labeling sensitive data for audit-readiness.
What is AI categorization?
While classification assigns a specific label to data, AI categorization organizes data into broader groupings or taxonomies — structured frameworks that define how information relates to other content types.
How it works:
- Categorization models group content by topic, department, sensitivity level, or other custom criteria.
- Unlike classification, categorization often reflects a multi-tiered structure, such as folders or data silos.
- Categorization may be dynamic, adjusting as new relationships or hierarchies emerge in the data.
Common use cases:
- Content management systems (CMS) — Automatically assigning website content to categories like news, events, or policy updates.
- Knowledge bases — Structuring FAQs or internal documentation by subject area for easier access.
- Regulatory reporting — Grouping documents by compliance categories (e.g., SOX, HIPAA, FERPA) to support audits and reviews.
AI categorization is especially helpful for large organizations that need to maintain strict information architecture standards, particularly in multi-department or multi-regulation environments.
By combining AI classification with AI categorization, organizations gain a more complete, accurate, and scalable way to manage their data lifecycle, from capture and retention to access and regulatory compliance.
Importance of AI Data Classification and Categorization in Regulated Industries
For organizations operating in heavily regulated sectors, the ability to classify and categorize data accurately is operationally and legally necessary. The risks of mishandling sensitive information can lead to audits, fines, legal exposure, and reputational damage.
AI classification and categorization provide a scalable and dependable way to meet compliance demands and protect brand integrity.
Compliance and regulatory requirements
Industries like healthcare, financial services, government, and K-12 education must adhere to strict legal frameworks:
- HIPAA (Healthcare) — Requires the protection of Protected Health Information (PHI), including strict guidelines on storage, access, and disclosure.
- FINRA, SEC, SOX (Financial services) — Demands financial transparency and secure retention of electronic records.
- FERPA (Education) — Mandates privacy of student records and communications.
- FOIA and State Sunshine Laws (Public sector) — Require timely access and production of public records upon request.
For them, AI data classification supports compliance in several ways:
- Accurate labeling — Automates the tagging of records as confidential, PHI, financial, or educational under applicable laws.
- Retention management — Ensures records are preserved or purged based on legally defined schedules.
- Audit readiness — Enables fast and accurate retrieval of specific communications or documents during an audit, investigation, or ediscovery process.
By automating classification, organizations reduce human error and demonstrate a consistent and defensible compliance posture.
Data security and risk management
According to surveys, 70% of cybersecurity professionals say AI proves highly effective for detecting threats that previously would have gone unnoticed.
Misclassified or uncategorized data often flies under the radar, which creates blind spots for security teams and increases risk.
AI categorization directly contributes to a stronger security posture by:
- Identifying sensitive content — Automatically detects data types that require encryption, access restrictions, or additional scrutiny, such as Social Security numbers, patient records, or internal HR memos.
- Preventing unauthorized access — Ensures that only authorized personnel can view or interact with sensitive or regulated data.
- Enabling risk alerts — Flags anomalies or content matching risk patterns, such as mass deletion attempts, inappropriate language, or non-compliant behavior.
AI classification also empowers proactive risk management strategies. For example, by identifying patterns in negative sentiment or unusual communication behavior, an organization can intervene before minor issues escalate into major compliance or HR problems.
AI Data Classification Techniques
AI-driven classification can take several forms, each with its strengths and ideal use cases.
Most modern classification engines combine multiple techniques to achieve better accuracy and adaptability.
Here’s a breakdown of the three primary methods, with real-world applications relevant to regulated industries:
Rule-based classification
Rule-based classification is the most straightforward approach. It relies on static, human-defined rules to determine how data should be labeled.
How it works:
- Uses “if-then” logic to trigger classifications.
- Rules are typically based on specific keywords, phrases, or metadata.
- No learning occurs — the logic is static unless manually updated.
Example use cases:
- Education — If a subject line contains “student grades” or “report card,” label it as “FERPA-sensitive.”
- Finance — If the file name includes “Q4 earnings” or “1099,” tag as “Financial Reporting.”
- Healthcare — Flag emails that mention “diagnosis”, “patient records”, or contain patient ID numbers as “PHI.”
Rule-based systems are highly transparent and easy to set up, but they don’t scale well for complex or large B2B datasets with ambiguous or evolving patterns.
Machine learning classification
Machine learning (ML) classification uses supervised learning models trained on historical data to identify patterns. The model learns from labeled examples and uses that knowledge to classify new, unseen data.
How it works:
- Requires a training dataset with predefined categories.
- Continuously improves as more data is labeled and fed back into the system.
- Can handle both structured and unstructured data.
Example use cases:
- K-12 schools — A model trained on flagged communications can learn to identify early signs of cyberbullying or harassment, even when explicit keywords aren’t used.
- Government — Automatically categorizing FOIA-relevant records based on past requests and document structure.
- Healthcare — Identifying variations in PHI mentions even when specific terminology varies between departments.
ML classification is adaptable and scalable, especially for dynamic or high-volume environments. However, it requires good data hygiene and enough labeled examples to train effectively.
Natural language processing classification
Natural Language Processing (NLP) focuses on understanding human language, context, intent, tone, and semantics. It’s especially powerful for classifying unstructured data like emails, chat logs, and transcripts.
How it works:
- Processes language at the sentence or document level to identify intent and emotional tone.
- Can combine syntactic parsing with named entity recognition, sentiment analysis, and context tracking.
- Works well when data lacks obvious structure.
Example use cases:
- Education — Flagging messages with potential threats or emotional distress by identifying context-specific phrases like “I can’t take this anymore” or “Everyone hates me.”
- Healthcare — Detecting compliance risks by analyzing tone or indirect disclosures in patient-provider communications.
- Finance — Recognizing fraud risks or compliance violations in trader communications by identifying aggressive language or mentions of prohibited terms.
NLP significantly enhances classification by recognizing nuance and context beyond simple keyword detection. It’s especially useful in detecting tone (e.g., “very negative”) or intent (e.g., “resignation risk”) — essential for proactive compliance and HR oversight.
Common Challenges and How to Overcome Them
Implementing AI data classification and categorization can yield significant benefits, but not without some operational and technical hurdles. Here are the most common challenges organizations face, along with practical strategies to address them.
Data privacy and security concerns
The challenge:
One of the biggest obstacles is the fear of exposing sensitive or proprietary data to third-party models, especially in industries governed by HIPAA, FERPA, SOX, or FOIA regulations.
The solution:
- Use proprietary or closed-loop AI models that run on-premises or in a private cloud environment.
- Ensure data classification tools are isolated per customer with strict access control layers (ACLs).
- Avoid sending data to public LLMs unless fully anonymized and contractually protected by vendor agreements.
Jatheon’s approach includes strict data residency controls and classification models that never share customer data across tenants, ensuring compliance with both legal and ethical standards.
Integration complexity
The challenge:
AI classification often requires integration across multiple communication and storage systems, such as email, chat, file storage, cloud platforms, and legacy tools.
The solution:
- Use platforms that offer pre-built connectors for various data sources — email, Teams, Zoom, WhatsApp, Slack, iMessages, and others.
- Choose vendors with robust API capabilities to enable future custom integrations.
- Build in staging environments first to test workflows before deployment.
A system-wide AI Index, like the one Jatheon is developing, reduces the need for manual segmentation and supports unified classification across diverse data types.
Lack of historical data for training
The challenge:
Machine learning requires a training set. If your organization doesn’t have well-labeled historical data, the model may produce inaccurate results early on.
The solution:
- Start with rule-based models to generate baseline labels.
- Use semi-supervised learning where AI suggests labels that humans can approve or reject, creating a labeled set over time.
- Partner with vendors who offer domain-specific training sets, especially for regulated industries.
Even a modest amount of labeled data (e.g., a year’s worth of archived emails) can help bootstrap an effective model.
False positives and misclassification
The challenge:
An AI system that flags too much irrelevant data can become a source of noise, leading to user frustration and decreased trust in the system.
The solution:
- Use multi-layered classification (rule-based + ML + NLP) to triangulate and validate tags.
- Implement a feedback loop where users can report or correct misclassifications.
- Continuously retrain the model with approved tags and corrections.
This makes the system more intelligent over time and better aligned with real-world context.
Regulatory uncertainty around AI
The challenge:
As governments consider new AI regulations (e.g., EU AI Act, ISO/IEC 42001, NIST), compliance teams worry about investing in tools that may later become non-compliant.
The solution:
- Choose vendors that follow emerging AI safety and governance frameworks.
- Document how your AI model works, including what data it uses and how classifications are applied.
- Consider undergoing internal audits or certification reviews to demonstrate accountability.
Being proactive about AI transparency gives your organization a reputational advantage and reduces legal risk.
How Does Data Classification and Categorization Work on Jatheon Cloud
Implementing AI classification isn’t just about deploying a model. We’re talking about an iterative, structured process that balances automation, control, and compliance.
At Jatheon, this process is being shaped by internal research, competitive benchmarking, and real-world functionality that aligns with what users actually need.
From manual tags to smart labels
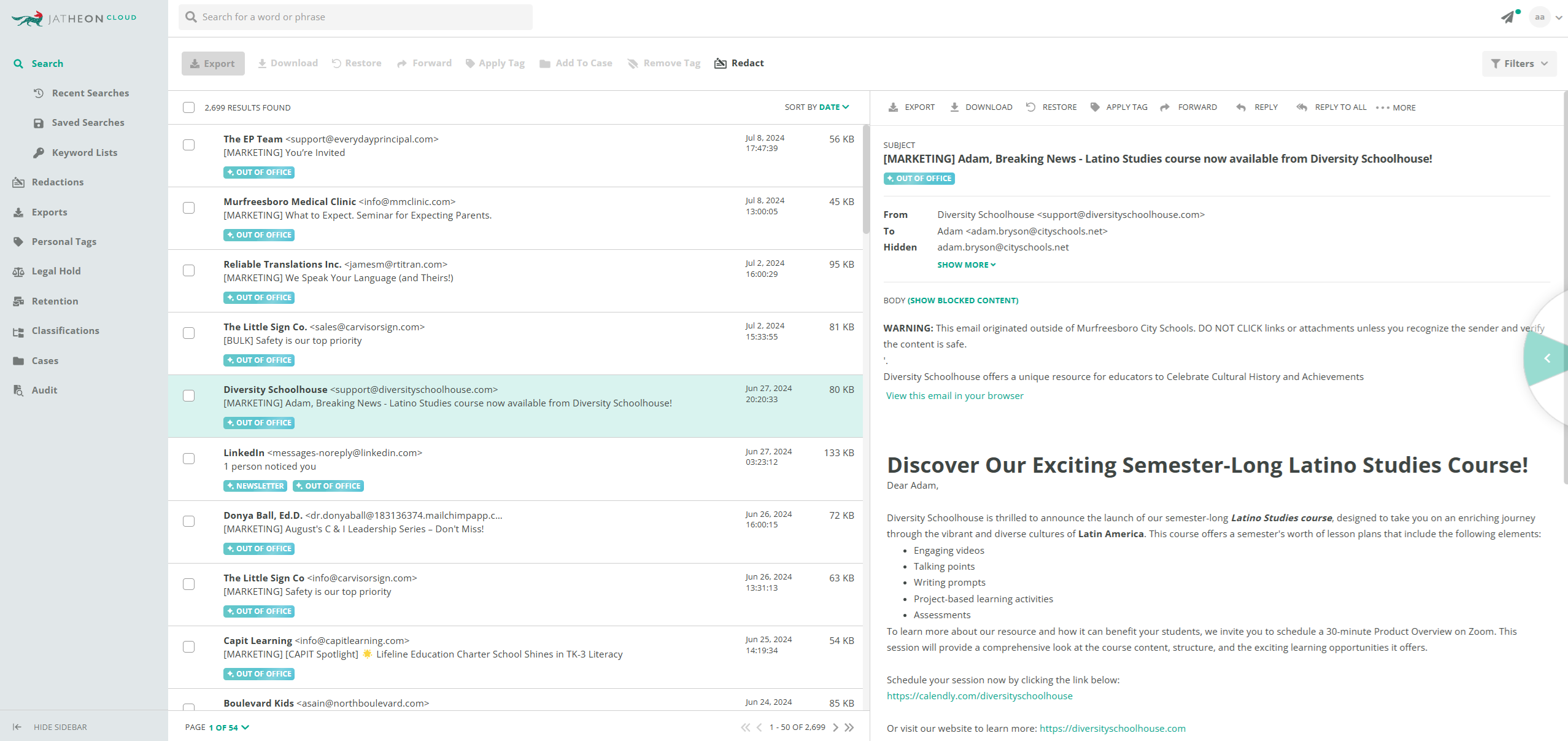
The foundation of AI classification at Jatheon starts with the ability to tag messages and files. Historically, users could manually apply classification tags. Now, AI-generated tags, like “Out of office” or “Newsletter,” will be system-generated and clearly labeled, making it easier for users to search, filter, and manage content.
Here are some examples of how this functionality works:
- AI-generated tags are separated from manual tags for clarity.
- Tags can be used as search filters (e.g., “Show only very negative emails”).
- Tags can trigger actions like alerts or policy checks.
Sentiment-based tagging
The next enhancement focuses on sentiment classification. Using modern large language models (LLMs), emails and messages will be tagged as “very negative,” “neutral,” or “positive” based on the content.
This functionality:
- Has been trained on real communication patterns to improve relevance.
- Is useful for identifying dissatisfaction, potential HR issues, or escalating risk.
- Can be filtered by compliance and security teams for further investigation.
Intelligent filtering for noise reduction
As part of the AI classification rollout, Jatheon is building specialized classifiers to help reduce irrelevant or repetitive content during searches and audits. These classifiers are designed to tag and isolate non-substantive messages that often clutter archives.
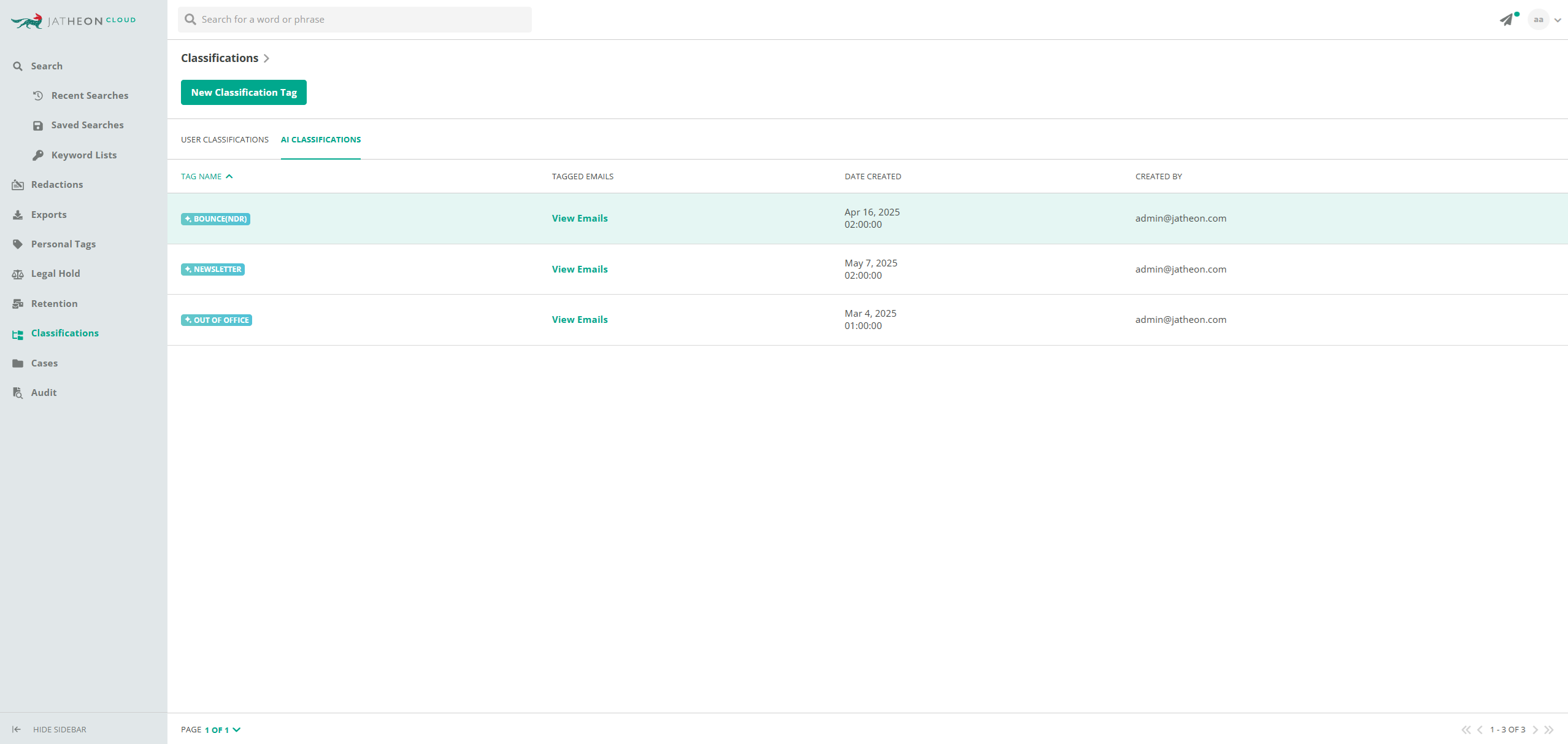
Here’s what’s already been released, in BETA, or on our roadmap:
-
- Bounce classifier — Automatically identifies bounced messages, tags them, and enables filters in search. Users can choose to either isolate all bounced emails, complete with the reason for the bounce, or exclude them entirely from results.
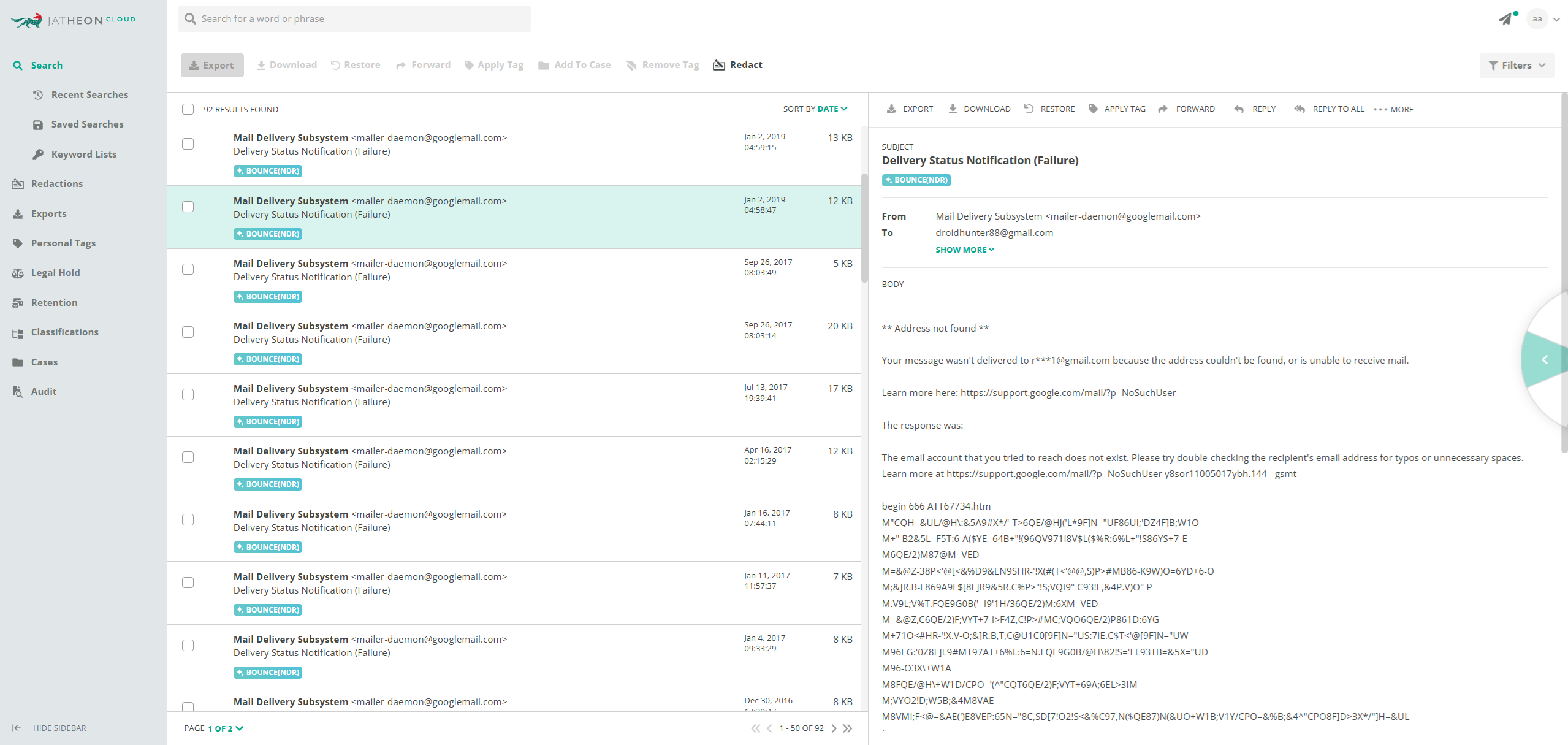
-
- Out-of-Office (OOO) classifier — Recognizes automatic replies and marks them accordingly. These replies can either be excluded from search results to avoid noise or retrieved exclusively if needed for analysis.
-
- Newsletter Classifier — Detects promotional and mass-email content, making it easy to filter out routine newsletters from results needed for compliance reviews.
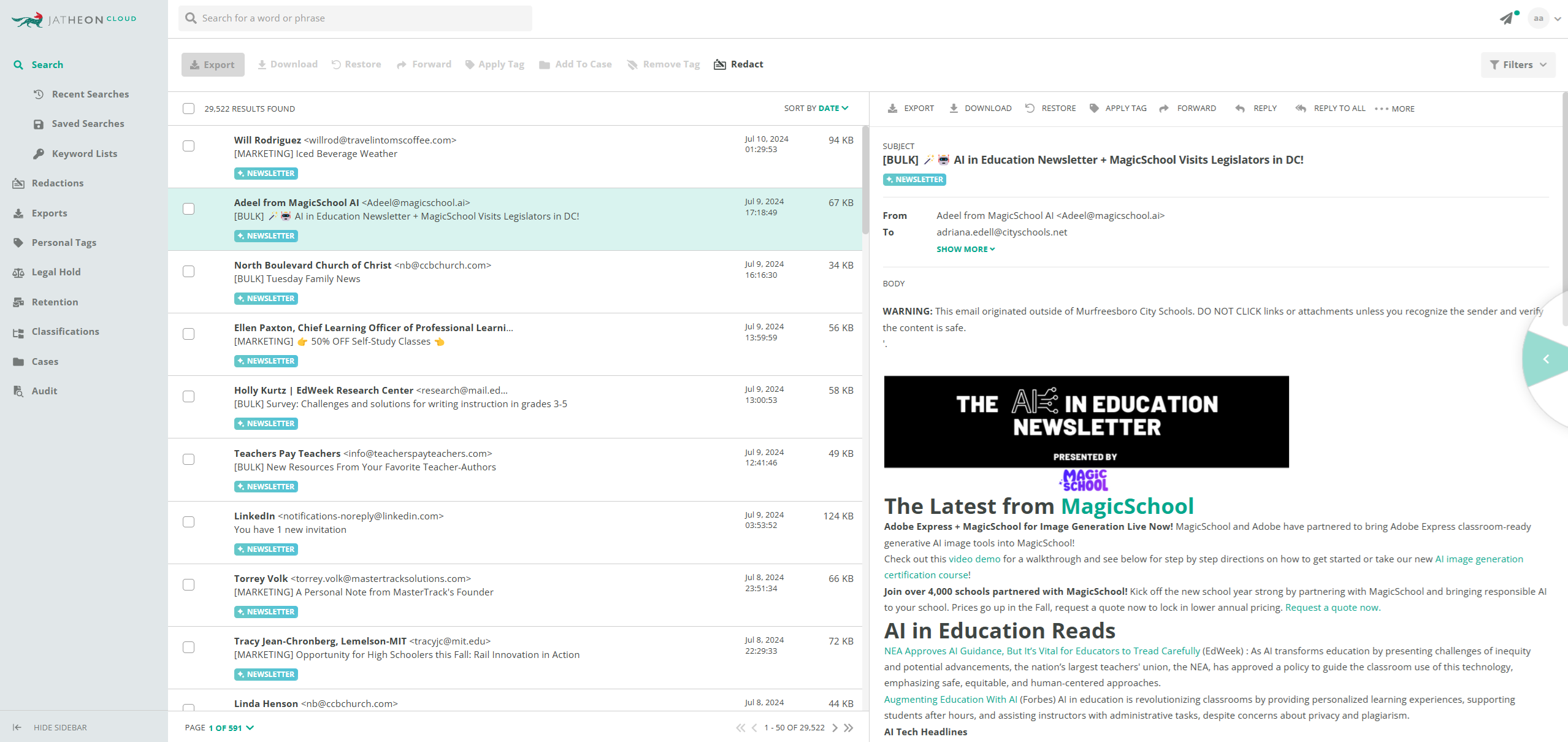
These classifiers not only improve the precision of AI-enhanced search but also streamline workflows for compliance teams who need to focus on actionable communication.
System-wide AI indexing
Jatheon is introducing a separate AI Index, which is distinct from its traditional search index. This enables AI to classify and analyze across all data sources (email, Teams, WhatsApp, iMessage, etc.) simultaneously without needing users to segment their searches by data type.
AI indexing provides:
- Unified classification across communication channels.
- Real-time tagging based on incoming data.
- Scaling across file types and formats.
Real-world use cases and context-aware intelligence
The classification engine isn’t built in isolation but informed by real scenarios:
- Risk signals, such as mass deletions or a sudden drop in user activity on platforms like Slack.
- Corporate policy awareness, allowing the system to apply company-specific definitions (e.g., what constitutes “bullying” or “insider threat”).
- Eventually enabling predictive queries such as: “Who are the three employees most likely to leave?”
This context-awareness moves classification from static labels to dynamic intelligence.
Air-tight search integration
Once classified, data becomes easier to manage through AI-enhanced search:
- Combine tags with search queries (e.g., “Files from last month with “Very Negative” sentiment”).
- Use tag-based filtering to streamline FOIA or legal discovery processes.
- Enable alerts for classified content that matches risk or compliance thresholds.
This classification process ensures that AI not only accurately identifies content but also makes it immediately useful for compliance, legal, and IT teams without adding complexity.
Summary of the Main Points
- AI data classification assigns specific labels to data, while AI categorization groups data into broader, structured categories for easier navigation.
- This helps organizations meet compliance obligations like HIPAA, SOX, FINRA, FERPA, and FOIA, reduce legal risk, and improve audit readiness.
- Rule-based classification uses static logic (e.g., keywords or metadata) to tag data, offering transparency but limited flexibility.
- ML classification trains on labeled examples to identify patterns and apply labels automatically, improving over time with use.
- NLP interprets context, tone, and meaning in unstructured text, supporting sentiment tagging and advanced policy detection.
- Common implementation challenges include data privacy concerns, integration difficulties, limited training data, false positives, and regulatory uncertainty.
- These issues can be addressed through private AI environments, API-ready platforms, hybrid classification models, user feedback loops, and adherence to emerging AI standards.
- Jatheon’s AI classification includes smart tagging like “very negative,” or “newsletter”, bounce and out-of-office classifiers, and a system-wide AI Index for cross-platform analysis.
- Once classified, data becomes easier to search, filter, and act on, supporting compliance, ediscovery, and risk monitoring while saving time.
FAQ
How does AI classification help with regulatory compliance?
It ensures consistent, accurate labeling of sensitive data like PHI or financial records, supports audits, and enforces retention and access policies.
Is AI data classification safe for sensitive data?
Yes, if using private, non-public models with access controls. Look for vendors who offer isolated cloud or on-prem deployments for added security.
Will AI misclassify data or produce false positives?
It’s possible, but combining rule-based logic, machine learning, and NLP reduces errors. User feedback loops also help refine accuracy over time.
Read Next:AI Audio and Video Transcription on Jatheon Cloud Optical Character Recognition (OCR): Impact on Compliance & Ediscovery |